前沿:迎接Prep 的fixed LOD吧!
——我的Tableau书稿(非最终版本)
1、聚合的必要性和用法
如果要我选一个Prep Builder远胜于desktop的一个功能,我愿意把这个殊荣授予“数据聚合”。前面我们说,数据分析的关键是分析问题所在的数据层次,并将其聚合。这个过程在Desktop中是通过日期切片和度量聚合来完成的,不过这个聚合依然是从数据库的明细数据中聚合而来。如果我们要定期给CEO展示不同品类和总公司的销售汇总,每次都从千万甚至过亿行的数据聚合,会给数据库过多的压力。Desktop通过设置数据提取以及增量刷新,尽可能减少数据库计算的次数,提高访问性能。但如果我们要在很多个分析场景中反复使用这个对应的数据聚合呢?
此时我们就应该求助于Prep,作为敏捷ETL工具,Prep可以随时“按需聚合”,聚合的结果可以作为独立的数据源被反复引用,如果结合数据提取,那么就进一步提高数据被重复使用的效率。可见,prep可以被作为“流程化的数据仓库”来使用,prep可以创建一个反复使用的数据流程,按需创建、修改灵活、引用方便、支持提取,因此可以大幅度提高数据的利用效率、减轻数据库的计算压力。在在这个过程中,关键的功能就是聚合。
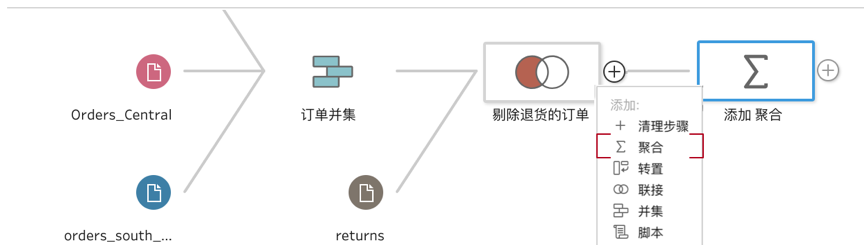
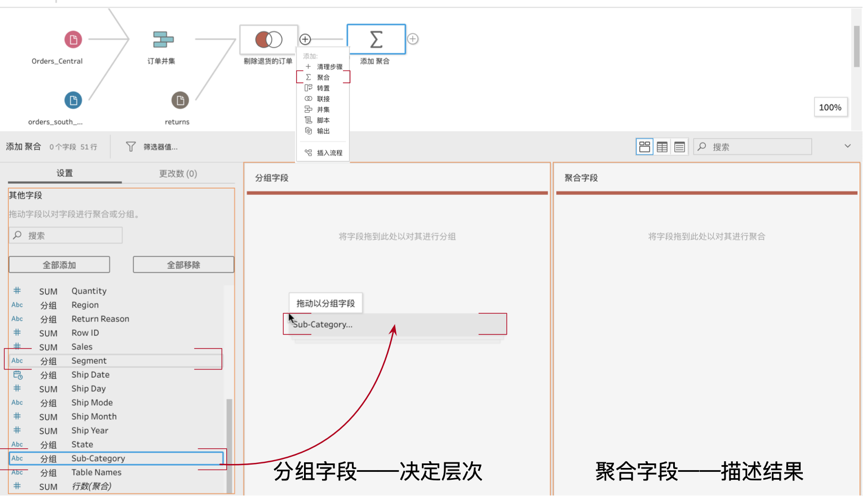
前面我们说,聚合的背后是层次。因此创建聚合务必清晰计算的数据层次,是创建每个区域、每天的销售聚合,还是创建每个门店、每个品类、每天的销售聚合?按需创建的第一步是清晰需求。假设我们要将此前剔除退货后的正常订单,在以下的层次上做度量的聚合:每个类别(category)、每个子类别(sub-category)、每个细分(segment)、每个月的销售额、利润、数量和折扣。首先在此前的流程节点上添加一个新节点“聚合”,如下图所示。 接下来就要点击新增加的“聚合”节点,设置聚合字段了。代表层次的是需求中的维度字段,而聚合的通常是度量字段,将二者分别拖拽到右侧的分组字段和聚合字段区域,维度会展开为分组,度量会按照维度的分组聚合为数字,Prep Builder即可完成聚合过程。
接下来就要点击新增加的“聚合”节点,设置聚合字段了。代表层次的是需求中的维度字段,而聚合的通常是度量字段,将二者分别拖拽到右侧的分组字段和聚合字段区域,维度会展开为分组,度量会按照维度的分组聚合为数字,Prep Builder即可完成聚合过程。

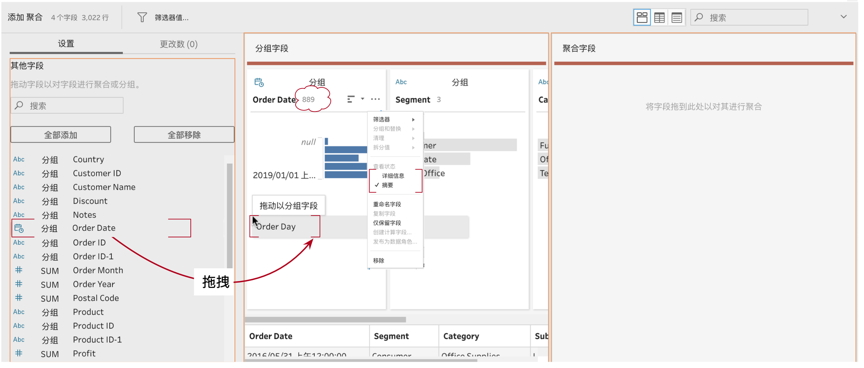
在聚合中有一个关键维度是日期,日期是非常特别的字段,它不仅自带层次结构,而且具备度量的连续性质。因此,日期既可以用来做聚合的层次,还可以用来创建坐标轴。在这里,我们要在“每个月”的层次上聚合多个度量,不过当我们拖入日期(order date)后,注意,默认是以“摘要”的方式显示,因此看到的五行数据完全不是总体,而只是按照年度的摘要,而order date旁边的“889”才是真正的数据唯一值的数量。
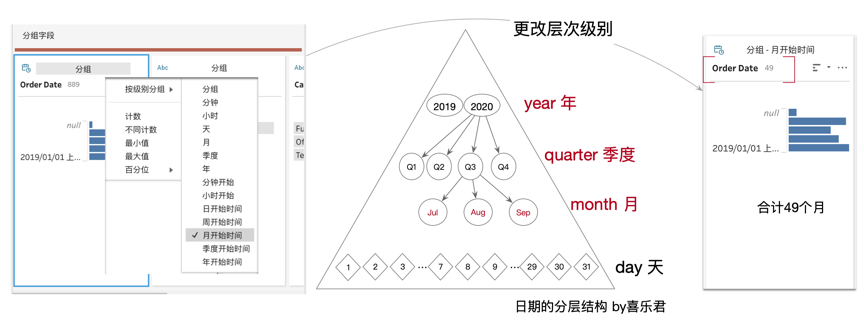
因此,我们需要把日期从明细日期(年月日时分秒),提高到更高的层次(年月),这里就需要点击“分组”,调整日期的层次。也就是依据需求中的日期层次结构分组,而非按照数据源的明细分组。这里我们要聚合到“每个月”,比如2019年1月、2019年2月,需要选择“月开始日期”,也就是把每个月内的所有日期都截断到月,后面我们讲解日期函数时,会特别说明这个选项背后的日期函数——datetrunc()函数。
之后,我们把需求中的度量字段拖入右侧的度量字段即可完成。务必通过聚合后各个字段的行数来判断数据聚合的准确性。
2、在Prep中做聚合时,特别注意几点
(1)维度才决定详细级别,因此加入度量并不会更改数据的详细级别,不会增加数据的行数,只是从此前的“4个字段,1399行”改为了“8个字段,1399行”;度量只是增加了数据的标记数量。
(2)维度也可以加入右侧的聚合字段,因为分类字段是可以被聚合的(计数、最大最小值),比如我们看每个月有多少订单,可以把订单ID加入聚合字段,比如要看每个月有多少客户购买,可以把客户加入聚合字段(计数不同是客户数,计数是购买人次)。虽然技术上,度量也能加入分组字段,但通常没有实质意义,除非是像“年龄”这样身兼维度和度量两个类型的度量。
(3)聚合还可以间接起到移除字段的作用,相当于SQL查询,既减少了查询量,又实现了查询过程中的聚合。熟悉SQL的朋友,可以参考SQL语言中的group语法;实际上,这里之所以被称之为“分组”,大概率就是取了SQL中“group”之意。
(4)很多专业数据库的数据仓库,其实就是把频繁的聚合查询,以定期运行的方式提取到本地做了缓存,专业术语大概是“物化视图”,就是把定期把结果转化为实际存在的数据表,而非虚拟的查询过程。借助于Prep Builder的流程创建和Prep Conductor的流程发布功能,Tableau可以实现数据仓库的相关功能,并且可以在查询和物化视图之间随时切换,从而兼顾数据的实时性和读取效率。
3、迎接Fixed LOD新功能
在2019年拉斯维加斯的TC大会上,Tableau剧透了2020年的一个重大更新,就是把Desktop中Fixed LOD表达式迁移到Prep中来,这是我最为期待的功能之一。就在本书即将定稿之时,这个功能如期而至。
Fixed是“指定”之意,LOD是详细级别、层次,Fixed LOD表达式本质是指定层次的聚合,即Aggregation on fixed LOD。上面的“聚合”也是指定层次的聚合,二者有什么区别呢?
简单的说,通过Prep的“聚合”一次只能完成一个层次的聚合,而借助于Fixed LOD聚合,则可以在已有详细级别之上,指定其他层次完成聚合,因此fixed LOD完整意义是指定独立的层次完成聚合,这里的独立层次,是相对于当前数据明细级别的其他层次,即Aggregation on external fixed LOD。
当大家学习完最后“LOD表达式”章节,会更加深刻地理解这个过程。
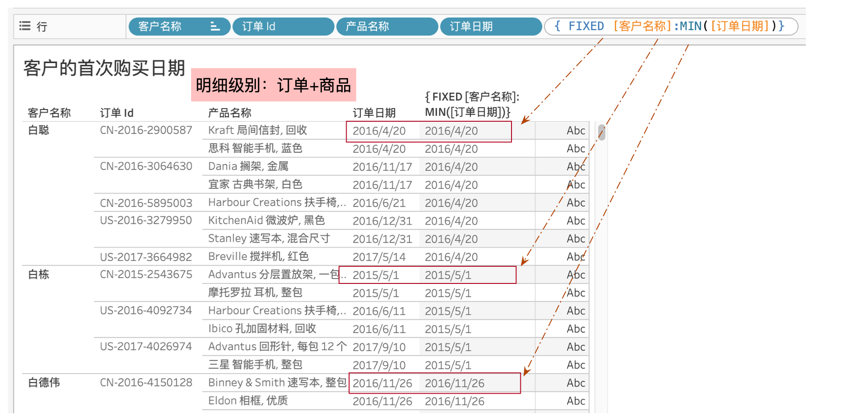
比如在商品交易为明细级别的超市数据中,我们想计算每个用户的首次购买日期。可以假想在Excel的明细中增加一个辅助列,不管这个客户购买过多少次交易,辅助列都显示它的首次购买日期。如下图所示:
在Desktop中,在视图详细级别(商品)上增加另一个完全独立的详细级别(客户)的聚合,只能通过fixed LOD表达式来实现,不过这个高级计算对于业务人员而言过于晦涩。IT或者少数高级分析师可以在数据整理时加入到数据整理的模型中来,简化其他人的操作,这就需要Prep了。
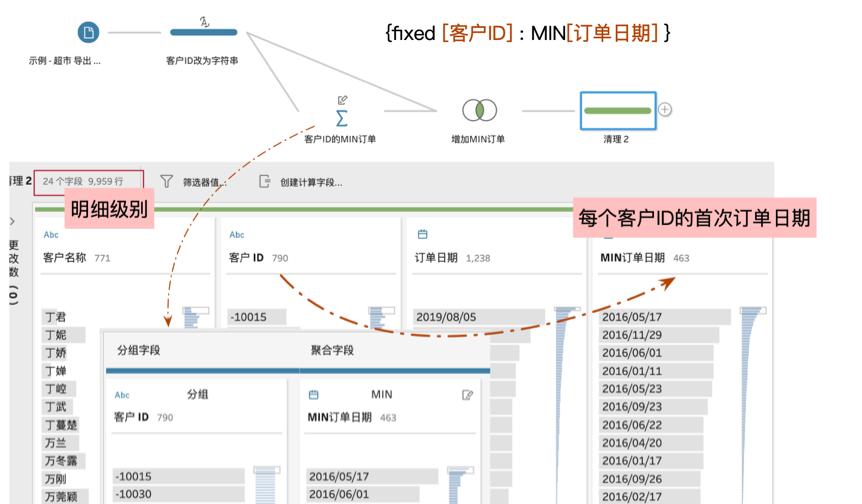
此前,Prep也能通过聚合间接实现上述的功能。原理是先计算每个客户的最小订单日期(聚合),然后再通过连接(join)把聚合结果关联到原数据后面。如下所示:
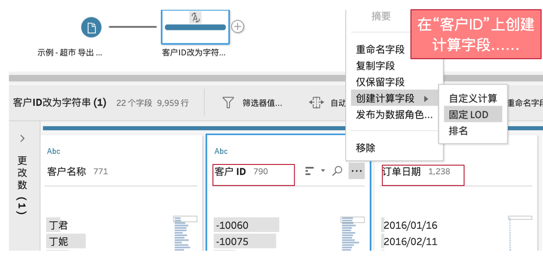
而在Prep Builder2020.1版本中“fixed LOD”的新功能,可以不经过聚合和连接两步操作,直接指定详细级别完成聚合,从而适合所有人轻松完成独立详细级别的聚合。
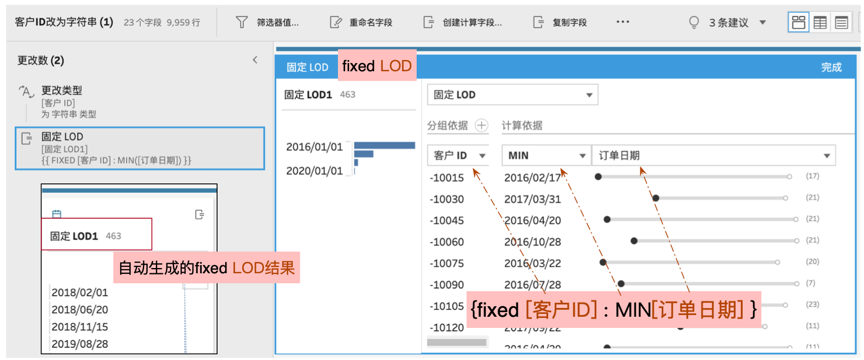
只需要在“指定详细级别”的字段,创建出计算字段即可。不过刚推出的版本翻译为“固定LOD”,会让很多人不知所然,如果改为Desktop中通用的Fixed LOD,有助于大家更好的理解。
在设置界面,Tableau设计非常友好,时间用坐标轴,最小值和最大值分别点击两侧即可快速拾取。注意左侧历史记录中的表达式,与后面的fixed LOD语法完全一致。注意通过字段右侧的数量来判断,和上面先聚合再连接(Join)的结果是一致的。
与Fixed LOD同时加入Prep计算的,还有高级计算之排名(rank)。这就可以把一部分复杂的数据整理过程从可视化环节前置到数据整理环节,更好的发挥专业分析师和IT部门的技术优势。
随着技术的平民化,分析师和企业就可以“用金钱换取时间”,从而获得竞争的优势。
了解 喜乐君 的更多信息
订阅后即可通过电子邮件收到最新文章。