本文属于“分析常识”系列文章之一:
- 1-分析常识:数据库、数据表、数据查询 ——所有工具背后的基础
- 2- 分析常识:分析的本质过程、问题的基本结构——适用于所有工具的分析过程
- 3- 分析常识-工具篇:从问题结构看SQL、DAX的共同性 ——基于新的框架理解SQL和DAX计算
- 4-分析常识-工具篇:DAX计算体系——计算的两大阶段、上下文体系 —— 数据准备与问题分析
- 5-分析常识:业务、分析角度看计算的基本分类(初级) —— 计算的基本分类
- 6- 分析常识:分析中的计算分类(高难度) ——字段计算的分类形式和分类矩阵
- 7-分析常识:分析查询的“表操作”_SQL为例(高难度) –计算的本质过程是“表操作”
在前一篇中,喜乐君从分析的本质——聚合——说起,介绍了问题的基本结构,以及它们对聚合的影响。从问题的角度看,问题的构成是“字段”,问题中计算的对象也都是“字段”(fields)。
理解字段的分类、计算、属性,是分析中至关重要的内容。 从业务角度看,字段对应业务对象(operational object),比如订单号、客户名称、产品ID等。从数据表角度看,字段构成数据表。
在一些BI工具,比如Tableau中,计算都就是针对字段的,例如[发货日期]-[订单日期], [Price ]* [quantity],SUM([sales])。而在另一些复杂的BI比如Power BI中,很多计算都要明示数据表,比如FILTER(table, condition),相对而言就更难以理解。
本文将从技术的角度,介绍字段计算的分类;下一篇(分析通识-5:分析查询的“表操作”_SQL为例(高难度))则介绍数据表的操作及其与字段计算的组合。
一、如何理解计算的有效性:语法、函数、环境
Mar 21, 2023 重写
在计算机和数据库中,所有的操作皆“计算”,常见计算的最佳算法内置为“函数”(built-in functions)。
在分析工具中,完全理解计算有效性有三个基本概念:语法(syntax)、函数(function)和 语境/上下文(context)。前面两种相对容易,语法syntax是工具中预设的,函数是常见计算的分类,它们都是客观的、预设的、甚至唯一的;难点在于理解计算有效性的环境,即语境/上下文(context),它是主观的,随着计算的位置、阶段,以及问题而变化。
- 语法syntax:是系统预设的规则,只有符合语法规范的计算才会被送往计算引擎执行;
- 函数function:是工具中内置的公式、是常用计算最优算法的“封装”,每个函数都有最佳的使用场景;
- 语境/上下文context:是计算有效性的背景,所有计算都相对于特定数据表而有效,又相对于特定问题而有业务意义。计算依赖的数据表和问题都要兼顾,毕竟,不是每个有效运行的计算都有业务意义,比如SUM([price])。
1)语法规则
既有表查询的语法规则,也有字段计算的语法,复杂计算中二者常常合二为一。以SQL为例,表查询必须遵照完整的查询语法,引用的函数也要遵循对应的函数规则。
如下所示,SQL查询有严格的语法规则,这个甚至优先于函数。只有整体的语法符合规范(比如字段后面要有逗号,数据库架构名称和表名称用点分开,SELECT-FROM-WHERE- GROUP BY遵循严格的书写次序等等),整个查询才会被执行,包含的函数才会执行运算。
-- aggregate table
SELECT Category,
Sub-Category,
SUM( Quantity ) AS TOTAL_Quantity
FROM tableau.superstore_en
WHERE Category= "Furniture"
GROUP BY Category,Sub-Category;查语法是唯一性规则,不符合语法规范的查询不会被执行。
2)函数
函数是特殊的计算,是最优算法的“计算预设”。计算和表达式都是函数的组合,虽然一个需求可能用多种函数完成,但每个函数都有最佳使用场景。初学者应该熟悉工具中的所有常见函数,方可“事半功倍”。
以分析中常用的SQL为例,使用如下的查询完成“2021年,不同类别、品牌的销售额总和、利润率”。在原始数据表中,既没有“年度”、“品牌”字段,更没有“利润率”(也不应该有这个字段)。在分析查询过程中,就要引用内置函数,完成“年度计算”(YEAR函数)“品牌计算”(SUBSTRING_INDEX拆分函数)和“利润率”计算(SUM聚合和/除法运算),用于弥补问题中所需。
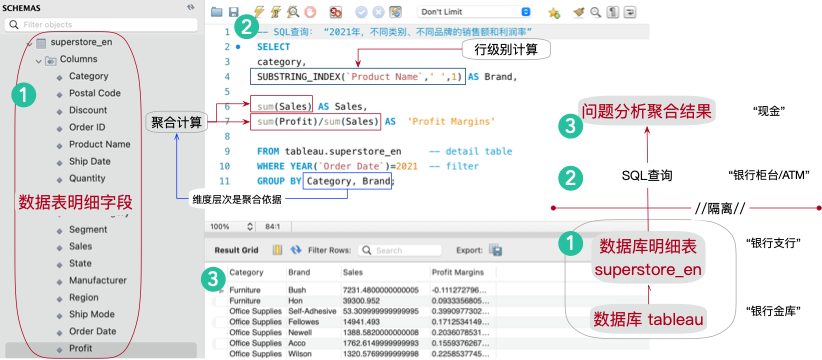
上述的每个函数都可以生成一个新的、临时字段,它们和数据表中已有字段不同,常称之为“逻辑字段”——在逻辑上名义的“有”、但在物理存储中实际“无”的字段。
函数的语法规则相对简单,可以按照功能不同快速识别,难点在于把它放在不同的语境中理解结果的意义。
3)语境/上下文
相比客观的、预设的语法和函数,计算的“上下文”则是主观的、多变的。程序中本没有“上下文”的概念,它是分析师为了理解计算的有效性环境而虚构的概念。
比如说,“利润率”来自于利润和销售额的比值,直觉计算方法就是“利润/销售额”。对计算稍有了解的读者就会知道这是不对的——因为数据表明细行中的“利润/销售额”计算虽然有值,但业务上绝无意义。 技术上有结果、业务上又有意义的利润率是“SUM(利润)/SUM(销售额)”;该计算相对于问题、问题聚合表而计算比值,代表每个品牌的利润率。
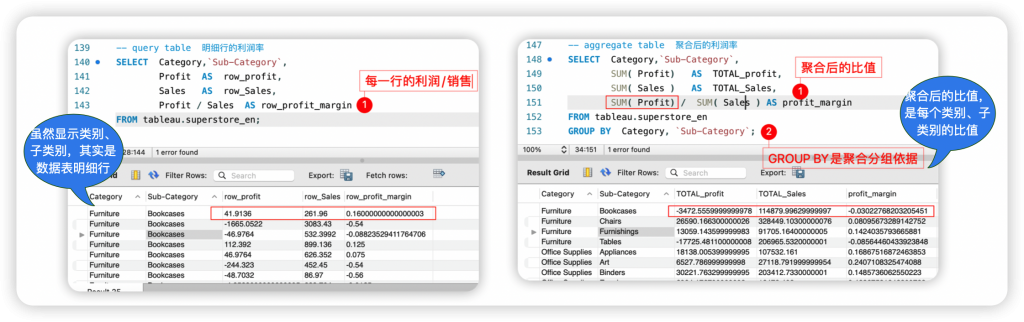
上述案例中,都是两个字段的比值,比值都是明细中两个字段值左右比较;区别在于,“利润/销售额”计算是建立在“数据表明细行”(detail row of base table)基础上的,“SUM(利润)/SUM(销售额)”计算是建立在问题聚合表的明细行(detail row of aggregate table)基础上的。
聚合表的明细行,是“底表明细行”分组聚合后的结果,二者具有严格的先后关系,因此是截然不同的环境。
从聚合角度看,有些计算是聚合前的详细级别,有些计算是聚合后的详细级别,这是SQL和Tableau的视角;换个角度看,每一个计算都有它执行对应的环境,称之为“计算上下文”“计算语境”(evaluation context),这是DAX的视角。
在英文中,计算所处的“环境”用Context表示,推荐翻译为“语境、环境”更易于业务用户理解。
在DAX中,计算列以“底表明细行”为计算依据,这类环境称之为Row Context;度量值相对于“问题聚合表”而存在,这类环境称之为Question Context或Filter context。。
- Row Context行上下文:计算相对于底表明细行而执行,这里的明细行就是计算有效性的语境/上下文
- Quenstion Context问题上下文:计算相对于问题级别而有意义,这里的问题就是计算有效性的上下文
在不同的工具中,会有差异化的名字,比如Query Context,Filter Context等等。
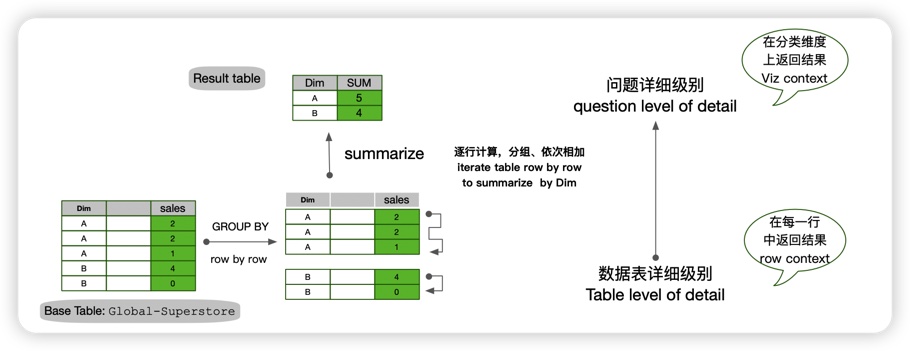
不过,喜乐君更喜欢用“详细级别”(level of detail)来表示计算所对应的环境,而非“Context/上下文”。详细级别是更适合业务用户理解的概念,而且更易于通往“多维分析”。
二、计算的分类矩阵:通往SQL和Tableau
前文讲,计算机中所有操作都是计算;数据分析中的计算首先是表计算(from table to table),这个部分在SQL中用SELECT和JOIN完成;其次是字段计算(filed calculation),大部分函数都是围绕字段展开,这是分析的重点。
这里先介绍字段计算的分类方式,而后逐一展开。
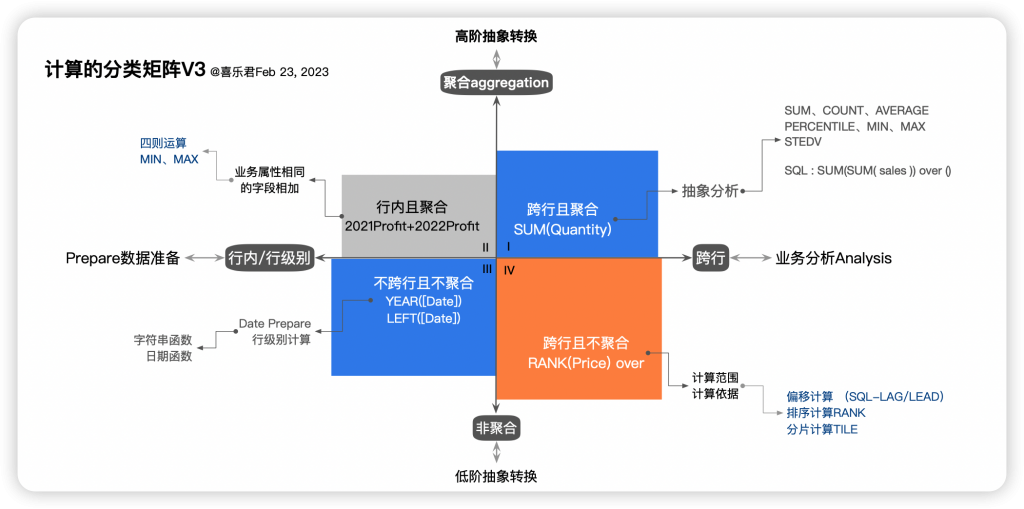
1、计算的分类矩阵:计算是否跨行(计算方向)、是否聚合(抽象程度)
Feb 22, 2023 重新整理,从一个数据表角度看分类矩阵
计算分类的关键在于指定分类标准,过于简单的标准无法覆盖复杂计算(比如排序),太过于抽象的标准则阻碍理解(比如以是否迭代区分函数)。而且分类应该遵循金字塔原理,相互排斥、不重不漏,从而具有通用的诠释能力。
这里以两个标准建立分类,其一是计算是否跨行,其二是计算是否聚合。
- 以计算过程跨行为标准,计算可以分为行内计算(行级别计算)和跨行计算。
- 以数据值是否聚合为标准,计算可以分为聚合计算和非聚合计算。
以此为依据,可以把计算分为四个象限,故称“计算的分类矩阵”。如下图所示:
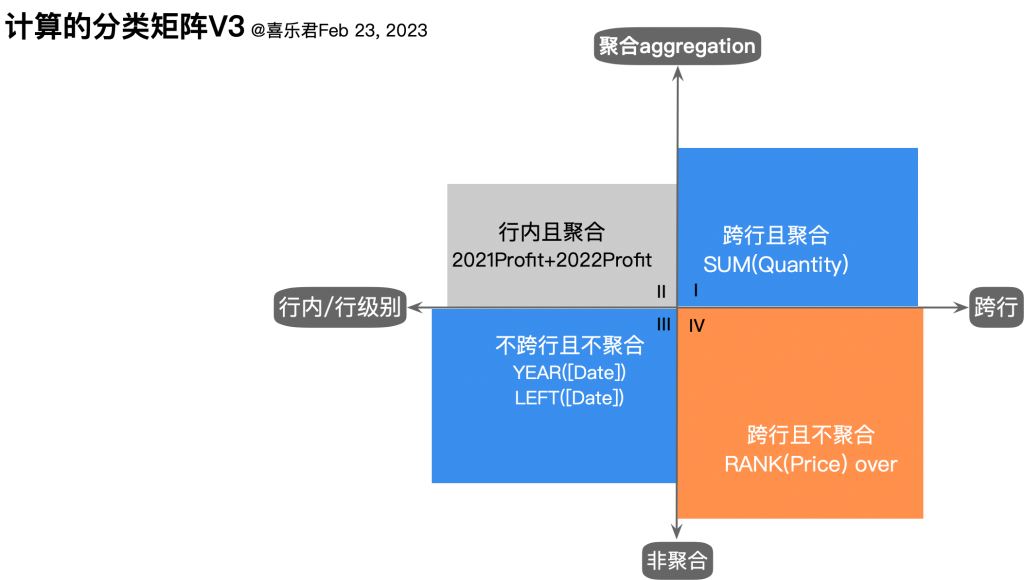
上述的两个标准,对应的是两个不同的视角,“计算是否跨行“对应数据计算的方向,而“计算是否聚合”对应计算结果相对于计算对象的抽象程度。
- 行内计算是数据准备计算,旨在弥补行级别业务对象的不足,另一个相同目的的是操作是数据表合并(join);相对应的,跨行计算是业务分析,它必然依赖于特定范围(partition)、特定依据(order),是对多行数据的抽象转换,也就不能直接对应到业务场景之中。
- 聚合计算意味着较高的抽象程度,比如一万行数据用100M代表其规模,相比之下,非聚合的抽象化程度较低,因为非聚合是数组到数组的计算,而聚合是多值到单值的计算。按照计算的方式,可以对计算的抽象程度做一个基本排序:
💡多遍聚合>>直接聚合>>跨行非聚合(排序) >>不跨行聚合( MAX(a,b))>>不跨行不聚合>>已有字段
为了帮助理解,接下来先在一个简单的Excel中完成上述四个矩阵的计算。不过要注意,这里的Excel计算仅作辅助解释,不考虑数据表规范。
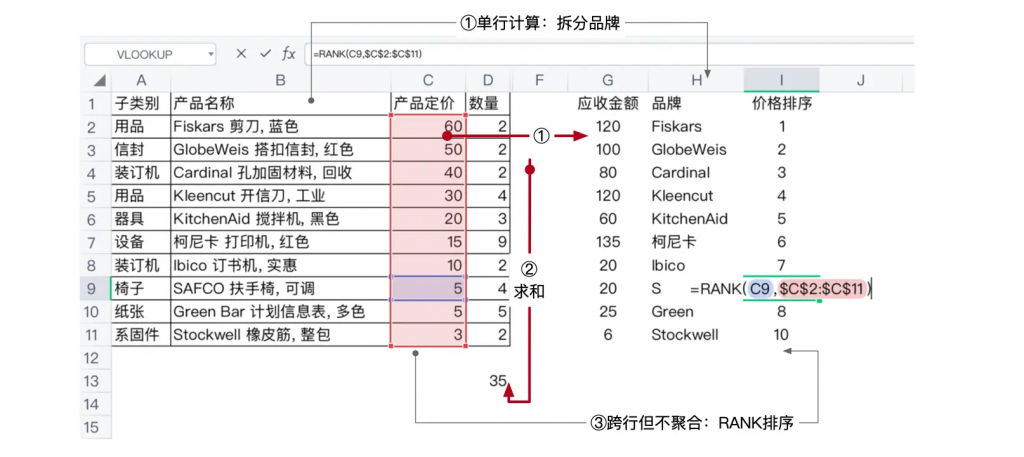
如下所示,从10行数据计算所有产品数量的总和(SUM),以及从产品名称中逐一拆分品牌(LEFT),这两个计算是典型的单行级别、非聚合计算;10行数据的数量相加,获得“数量总和”值,这个是典型的跨行、聚合计算;而将每一行的定价排序,10个值的数组依然返回10个值数组的过程,则是典型的跨行、非聚合计算。
也许会有人说,那行内的聚合呢?在规范的Excel数据中,这个计算并不常见,但在不规范的数据中则普遍存在,比如在如下的数据中计算每个产品、所有年度的销售额总和;或者计算每个产品的成交单价(以价格低的计算),前者使用了SUM(可以用加号代替),后者使用MIN函数(可以用if代替)。
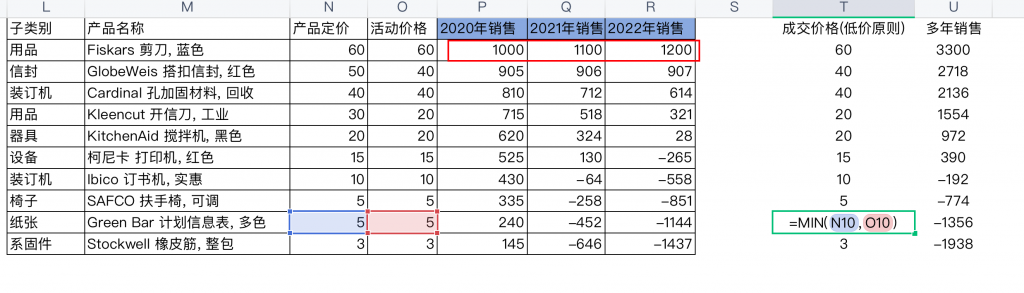
MIN和MAX是较为特殊的聚合函数,它们既可以实现行内两个值的比较,也可以实现列中所有数据值的比较。如同四则运算,可以在任意方向上计算。Excel的优势在于灵活,SUM求和可以在任意方向、任意单元格上组合使用,但在关系数据库中,SUM则面向单列使用,这也意味着,不跨行且聚合的形式变得非常有限。
沿着这样的分类方法,我们可以把常见的计算函数分类到不同的矩阵之中。如下图所示:
2、分类方式一:行内计算与跨行计算
数据表是记录行、字段列交叉构成的二维数组,其中记录行对应业务过程,字段列对应业务对象。计算既可能在记录的方向上展开, 也可能在字段列的方向上展开;前者的代表是A+B、A/B的算术计算,后者的代表是SUM([A])、DISCOUNTROWS(table)的聚合计算。
- 行内计算(row calculation):计算在单一明细行中有意义的计算
- 跨行计算(cross-row calculation):计算过程同时引用多行的计算。
这里先用熟知的Excel来理解。如下图所示,使用“销售额/数量”可以计算每一行的单价——单价在业务过程中是有意义的,不考虑折扣的情况下,单价可以视为吊牌定价。而使用“SUM(E2:E10)”可以跨行计算所有的销售数量,对应一个抽象的问题“所有产品的数量总和”。
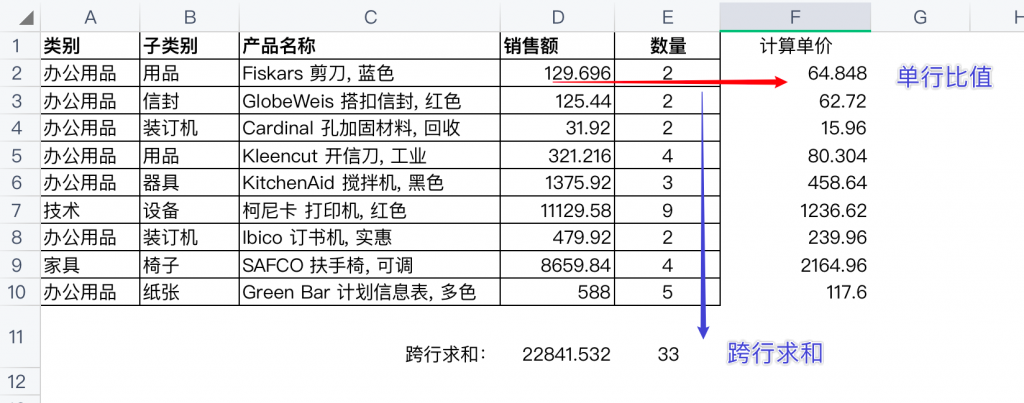
行内计算以字符串函数、日期函数为主,它们相当于数据明细数据的预先处理和转换;另外还有各类算数计算。比如:
- 字符串的截取、拆分、合并、查找、替换等操作
- 日期是特殊的字符串,日期的截取(datepart)、截断(datetrunc)、转换等操作
- 算术计算,包括四则运算、绝对值、幂、三角函数、精度控制函数(比如四舍五入)等。
其中,两个日期计算间隔(datediff)和日期增减数字间隔(dateadd)相当于特殊的算术计算。
常见的跨行计算可以分为如下几类:
- 针对单字段列的直接聚合函数,比如SUM、AVG
- 针对单字段列的排序函数,比如RANK,通常结合asc升序或desc降序
- 针对单字段列的偏移函数,比如SQL中的LAG和LEAD函数,Tableau的LOOKUP函数
上述计算又有所不同,聚合和排序无关范围,也无关次序,但排序结果有次序;偏移函数有范围而无次序。
相比行内计算的单值转换,行间计算完成同一个业务对象多个数据值的聚合或排序,因此说,后者的抽象化程度相比行内计算更高。
3、分类方式二:聚合计算与非聚合计算
SUM是最常见的聚合函数。虽然在Excel中,SUM函数可以实现任意单元格的求和,也可以针对行或者列区域完成求和;但在关系数据中,SUM函数主要面向字段列,对同一列中的所有数据值完成求和。
当然,聚合并非只有常见的SUM、AVG计算,它们默认对整个列所有值计算;高级的SUM还可以对聚合值的范围加以控制,这就是累计求和(running SUM)和移动平均(moving average)等高级的聚合计算。在Tableau表计算介绍中,喜乐君就把window函数按照范围的不同区分为三个类型。
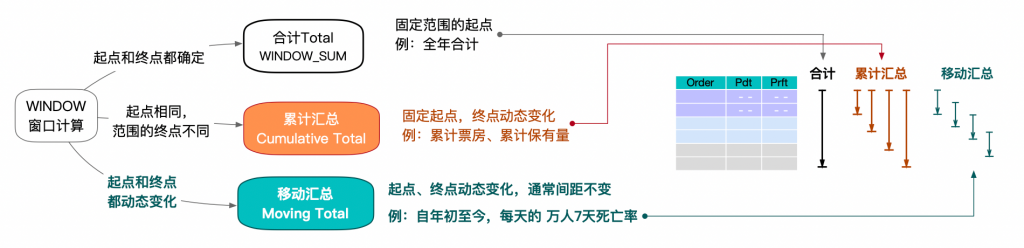
Tableau表计算应用范围较窄,仅能对聚合表完成二次聚合,而SQL则可以针对明细表直接完成二次聚合。这是Tableau表计算和SQL窗口计算的一个关键差异(当然Tableau是基于性能考虑)。
使用SQL查询MySQL数据表,可以完成上述三种聚合计算,over用于控制聚合的范围和依据。
SELECT `Order Date` , Sales,
sum(Sales) over (order by `Order Date` rows 2 preceding) as Moving_2row_sum,
sum(Sales) over (order by `Order Date`) as running_sum_by_dt,
sum(Sales) over () as Total_sum_by_table
from tableau.superstore_en
order by `Order Date`;需要注意的是,本案例中,一个日期会有多个金额,累计求和以日期为依据(order by),因此会出现同一日期数据相同的情况;反观移动平均,它使用rows 2 preceding控制范围,沿着日期计算字段与之前两个值相加。

虽然聚合一定跨行,但跨行不一定是聚合。跨行但不聚合的典型是RANK排序计算。
如下图所示,在Excel中使用RANK函数对【销售额】字段排序。为了确认11129.58是最大值,排序计算需要将其与其他数据行的每一个销售额比较,最后才标记为1。可见,排序计算不仅是跨行之间的比较,而且计算的次序要远比SUM(销售额)求和要多。
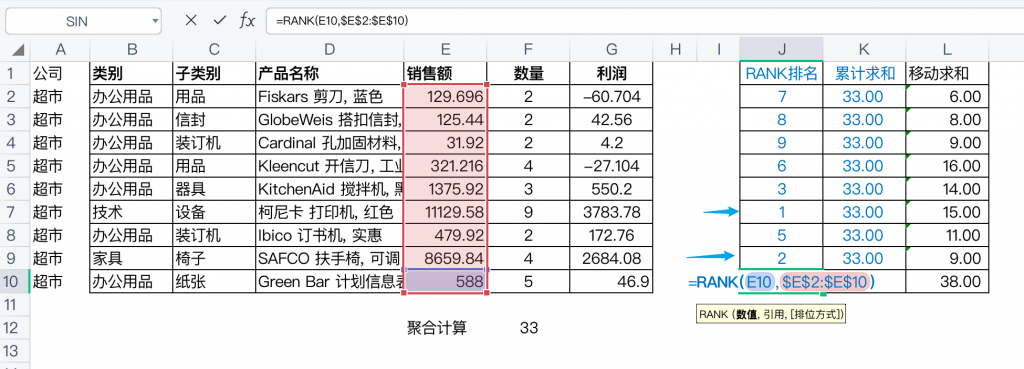
假设字段中有N个数据值,采用“选择排序”寻找最小值,在第1轮中需要比较n-1个数字,第2轮需要比较n-2个数字……到第n-1轮的时候就只需比较1个数字了。因此,总的比较次数都是(n-1)+(n-2)+…+1≈n2/2次。
相比之下,聚合函数仅需要N次就可以完成聚合计算。
除了排序,数据分析中还会遇到很多种高级的非聚合计算,常见的有:
- 排序RANK函数
- 索引函数,比如SQL中的ROW_NUMBER函数,Tableau的INDEX函数
- 偏移函数,比如SQL中的LAG和LEAD函数,需要配合OVER控制其范围和次序依据
- 分片TILE函数
后续内容,将发布在专为内部读者的平台。
喜乐君
Mar 11, 2023
Mar 19, 2023
Mar 21, 2023 重写第一部分
了解 喜乐君 的更多信息
订阅后即可通过电子邮件收到最新文章。
Pingback: 分析常识-1:数据库、数据表、数据查询 – 喜乐君
Pingback: 分析常识-2:分析的本质过程及聚合计算_SQL – 喜乐君
Pingback: 分析常识-3:工具篇之SQL、DAX计算体系 – 喜乐君
Pingback: 分析通识-5:分析查询的“表操作”_SQL为例(高难度) – 喜乐君
Pingback: 喜乐君-图书介绍 – 喜乐君
Pingback: 喜乐君-图书介绍与分享计划-喜乐君-敏捷BI布道师
Pingback: 《业务分析通识》_普适性的“业务分析框架”-喜乐君-敏捷BI布道师
评论已关闭。